Sweep case study
In Supervised Learning Hyperparameters, we introduced default hyperparameters as a starting point. While defaults are useful, optimal values are often task-specific. A hyperparameter sweep---systematically testing values across a range---is a more reliable way to identify the best settings for your use case.
This guide demonstrates how to sweep over the learning rate (LR) to find an optimal value.
Why sweep the learning rate?
The learning rate is typically the most impactful hyperparameter. While our default recommendations perform well (usually <0.5% regret), you can often achieve even better results by sweeping to find the task-specific optimum.
Setup
We use the simple supervised learning training loop in sl_loop.py, which trains a Llama-3.1-8B model.
To retrieve the model’s default learning rate recommendation:
from tinker_cookbook.hyperparam_utils import get_lr
print(get_lr("meta-llama/Llama-3.1-8B"))This should output
0.0002856415043086949 # ≈ 2.8e-4This default value provides a baseline. A common best practice is to sweep one order of magnitude above and below the default. For this case, we sweep over:
Running the sweep
Launch experiments in parallel, using separate terminal windows for each LR value. For example:
python -m tinker_cookbook.recipes.sl_loop learning_rate=0.003 log_path=/tmp/sft-lr-sweep/lr-0.003
python -m tinker_cookbook.recipes.sl_loop learning_rate=0.001 log_path=/tmp/sft-lr-sweep/lr-0.001
python -m tinker_cookbook.recipes.sl_loop learning_rate=0.0003 log_path=/tmp/sft-lr-sweep/lr-0.0003
python -m tinker_cookbook.recipes.sl_loop learning_rate=0.0001 log_path=/tmp/sft-lr-sweep/lr-0.0001
python -m tinker_cookbook.recipes.sl_loop learning_rate=0.00003 log_path=/tmp/sft-lr-sweep/lr-0.00003
python -m tinker_cookbook.recipes.sl_loop learning_rate=0.00001 log_path=/tmp/sft-lr-sweep/lr-0.00001You can also automate this process by writing a script that spawns multiple tmux windows and launches experiments programmatically. This is especially useful for larger sweeps.
Collecting Results
After the experiments are complete, you can read the metrics.jsonl files:
from glob import glob
import pandas
import os
import json
data = []
for fname in sorted(glob(os.path.expanduser("/tmp/sft-lr-sweep/*/metrics.jsonl"))):
df = pandas.read_json(fname, lines=True)
# make sure the experiment is completed
if len(df) == 0 or df["progress"].iloc[-1] < 0.98:
continue
config_fname = fname.replace("metrics.jsonl", "config.json")
with open(config_fname, "rb") as f:
metadata = json.load(f)
data.append({
"fname": fname,
"learning_rate": metadata["learning_rate"],
"final_loss": df["train_mean_nll"].iloc[-1].item()
})
print(f"Read metrics for {len(data)} experiments")If all the experiments are completed, the above code should print:
Read metrics for 6 experimentsVisualizing the Sweep
Plot the final_loss as a function of learning_rate:
import matplotlib.pyplot as plt
df = pandas.DataFrame(data)
plt.plot(df["learning_rate"], df["final_loss"], marker='o')
plt.axhline(y=df["final_loss"].min(), color="green", linestyle="--")
plt.ylim(1.65, 1.8)
plt.xscale("log")
plt.xlabel("Learning Rate (log scale)")
plt.ylabel("Final Loss")
plt.title("Final Loss vs Learning Rate")
plt.show()You should see a U-shaped curve, similar to this:
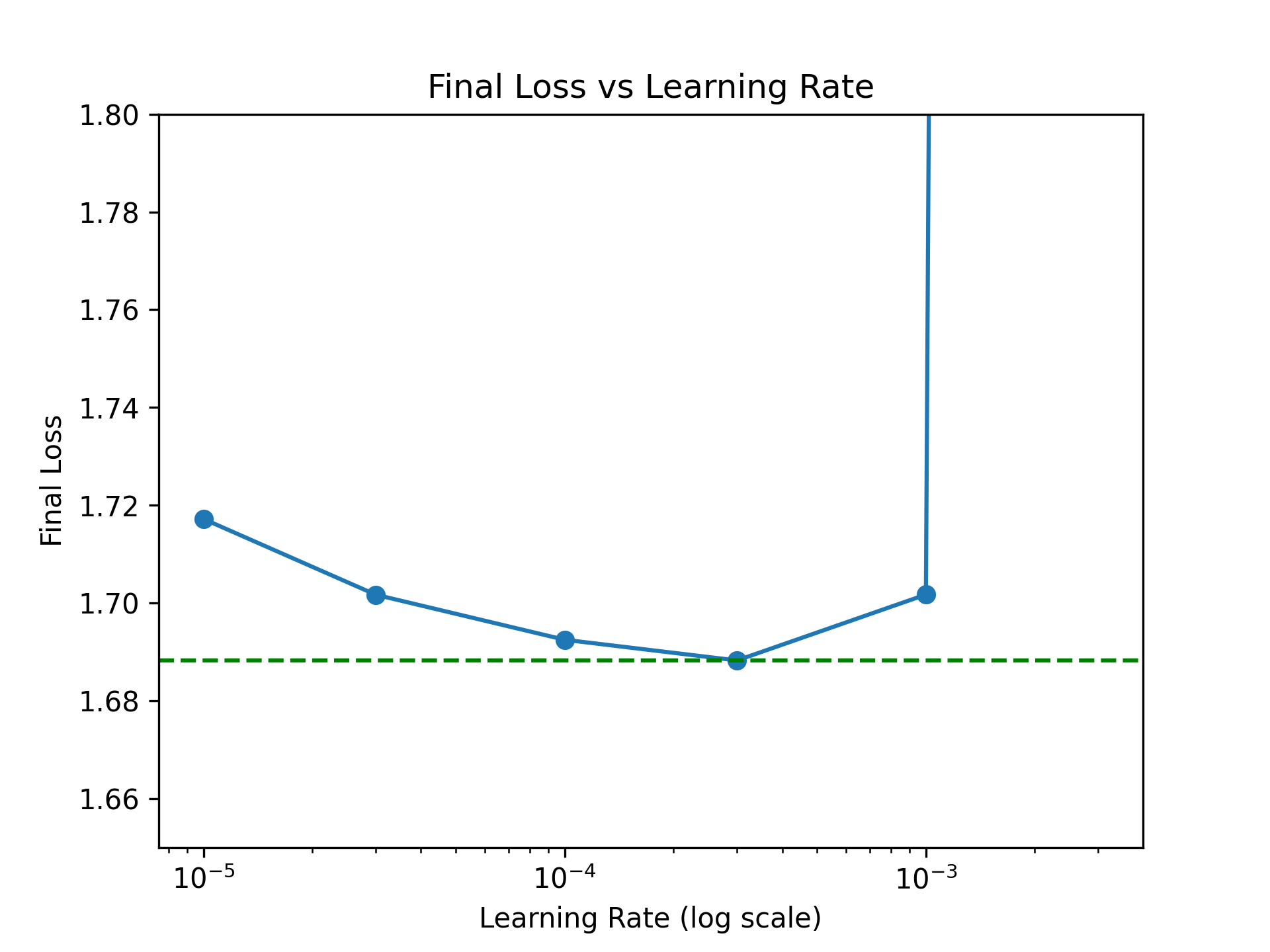
If the full U-curve is not visible in your setting, expand the sweep range by adding more LR values.
Determining the Optimal LR
The optimal learning rate is the one that minimizes the loss. The plot above shows that the optimal LR is 3e-4 which you can also calculate by finding the minima:
optimal_lr = df["learning_rate"][df["final_loss"].idxmin()]
print(f"The optimal LR is {optimal_lr:.2e}")Expected output:
The optimal LR is 3.00e-04Note that the optimal LR in our sweep (3e-4) is very close to the default LR (2.8e-4). However, task-specific sweeps can still provide marginal improvements and greater confidence in your hyperparameter choices.
Next steps
Now that you've identified the optimal learning rate:
- Retrain with the optimal LR for your production run
- Consider sweeping other hyperparameters like batch size, warmup steps, or weight decay
- Use the optimal LR as a baseline for future experiments on similar tasks